Types of learning
Model architectures
Scaling things up

Types of learning
Supervised learning
Training set of example input/output \((x_i, y_i)\) pairs
Goal:
If \(X\) is the space of inputs and \(Y\) the space of outputs, find a function \(h\) so that
for each \(x_i \in X\), \(h_\theta(x_i)\) is a predictor for the corresponding value \(y_i\)
(\(\theta\) represents the set of parameters of \(h_\theta\))
→ i.e. find the relationship between inputs and outputs
Examples:
Continuous outputs: Regression
Discrete outputs: Classification
Unsupervised learning
Unlabelled data (training set of \(x_i\))
Goal:
Look for structure within the data
Examples:
Clustering
Social network analysis
Market segmentation
PCA
Cocktail party algorithm (signal separation)
Self-supervised learning
Mostly used in Natural Language Processing (NLP):
Unlabelled data (e.g. raw text from the internet) is used by a model for training, for instance by predicting which words will come next in a sentence and calculating a loss function with the word that actually comes next.
Not needing labelled data is a huge advantage and SSL is starting to be used in computer vision as well.
Learning process
Bias
Allows to shift the output of the activation function to the right or to the left
Gradient descent

Iterative optimization method
Adjust the weights and biases
Batch gradient descent
Use all examples in each iteration
Slow for large data set:
Parameters adjusted only after all the samples have been through
Stochastic gradient descent
Use one example in each iteration
Much faster than batch gradient descent:
Parameters are adjusted after each example
But no vectorization
Mini-batch gradient descent
Intermediate approach:
Use mini-batch size examples in each iteration
Allows a vectorized approach that stochastic gradient descent did not allow
→ parallelization
Variation: Adam optimization algorithm
Major pitfall: over-fitting

Some noise from the data extracted by the model while it does not represent general meaningful structure and has no predictive power
Major pitfall: over-fitting
- Training too long
- Training without enough data
- Too many parameters
Overfitting: solutions
Regularization by adding a penalty to the loss function
Early stopping
Increase depth (more layers), decrease breadth (less neurons per layer)
→ less parameters overall, but creates vanishing and exploding gradient problems
Neural architectures adapted to the type of data
→ fewer and shared parameters (e.g. convolutional neural network, recurrent neural network)
Architectures
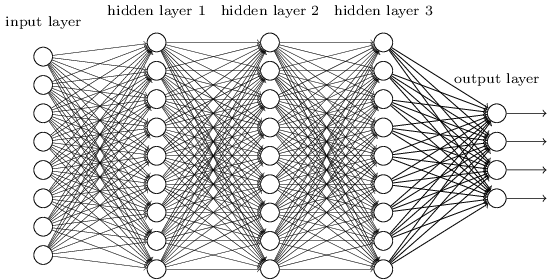
Fully-connected feedforward single-layer

Fully-connected feedforward deep NN
Convolutional neural network (CNN)
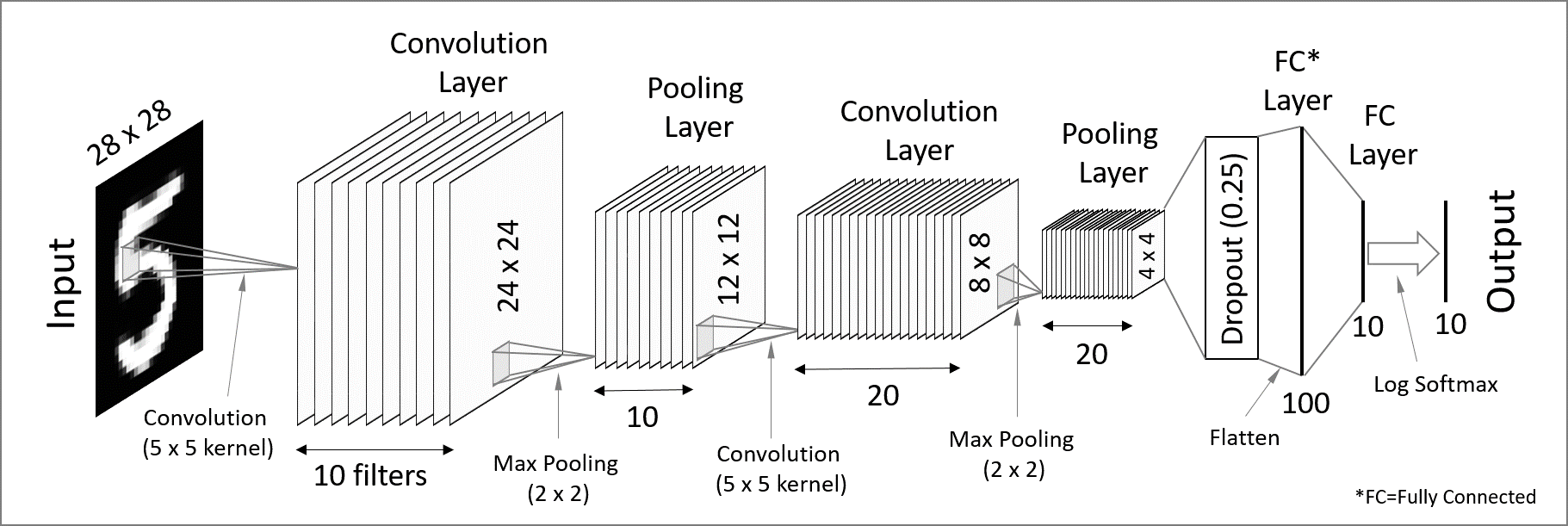
Used for spatially structured data (e.g. image recognition)
Convolution layers → Each neuron receives input only from a subarea (local receptive field) of the previous layer.
Pooling → Combines the outputs of neurons in a subarea to reduce the data dimensions. The stride dictates how the subarea is moved across the image (e.g. max-pooling uses the maximum for each subarea).
Convolutional neural network (CNN)
Recurrent neural network (RNN)

Used for chain structured data (e.g. text)
Recurrent neural network (RNN)
Transformers
Transformers
They allow for easier parallelization of tasks because the data processing order doesn’t matter
Transformers started in 2017 and have since then lead to the most complex models such as BERT and GPT-3
You will watch a video explaining their complex architecture
Scaling up
GPUs
- Does not help when memory is a problem
- Expensive. Not always available
Parallelization
- Sometimes not possible (e.g. RNN very difficult to parallelize)
- Sometimes the limiting factor is memory
Gradient accumulation
- Takes time
- Does not solve the problem if not enough memory for a single sample
Transfer learning
The topic of the next lesson
Transfer learning allows to repurpose models to new (similar) purposes, saving tremendous amounts of computing time and need for data
Implementations
ML libraries
Most popular:
- PyTorch
, developed by Facebook’s AI Research lab
- TensorFlow , developed by the Google Brain Team
Both most often used through their Python interfaces
Julia syntax is well suited for the implementation of mathematical models
GPU kernels can be written directly in Julia
Julia’s speed is attractive in computation hungry fields
→ Julia has seen the development of many ML packages